
Bio
- I am now a PhD student at University of Technology Sydney, supervised by Prof. Yi Yang and A/Prof. Linchao Zhu. I received my Master's Degree at Zhejiang University, where I was very fortunate to be advised by Prof. Deng Cai. Before that, I got my Bachelor's Degree at Huazhong University of Science & Technology, where I was also a member of IA Team, Qiming College.
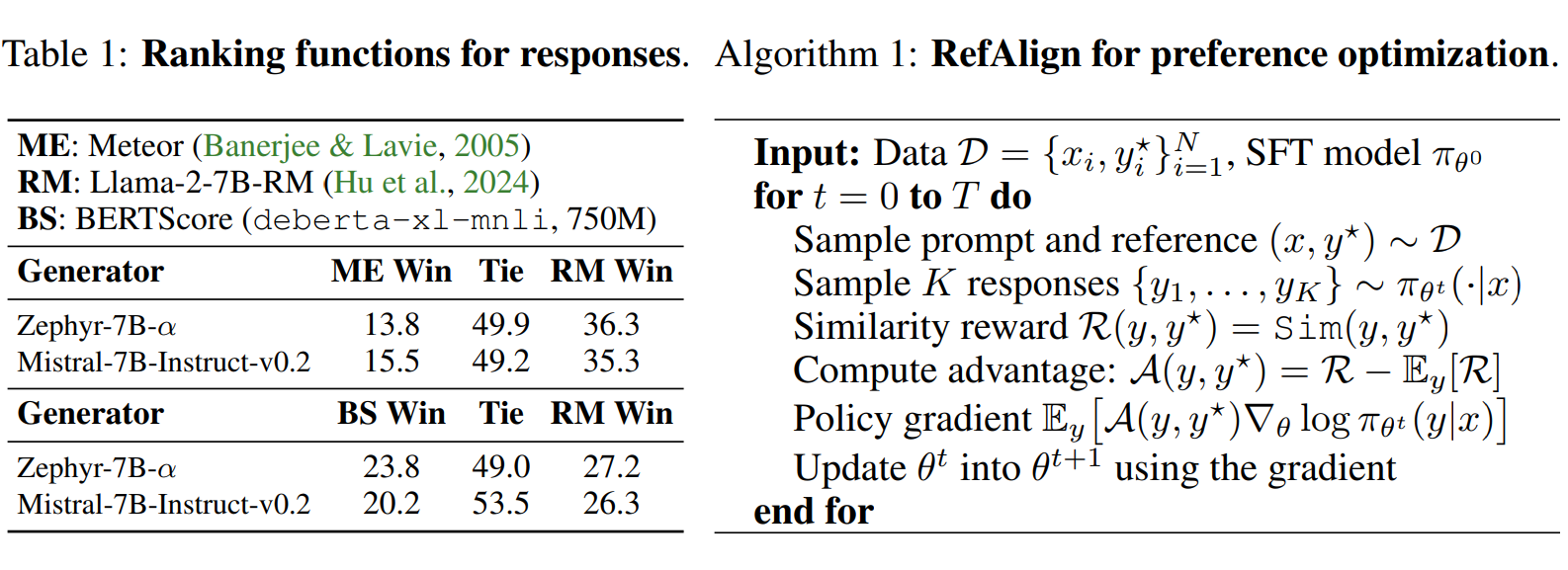
- My research interests involve machine learning and foundation models. Currently I am focusing on language model alignment. I believe reward functions are the core of language model alignment. Basic RL algorithm should be enough in most alignment cases, and I want to explore more possibilities of reward functions to make alignment more accessible. One of my efforts in this direction is RefAlign, RL with similarity-based rewards without traditional binary preference data.
- Previously, I am interested in exploring the transfer learning ability of vision-language models. For example, RLCF, very first Test-Time RL method with CLIP reward, A GRPO-like RL algorithm is applied in the image captioning task in the early of 2023; CLIP4STR, a strong STR baseline, demonstrating the power of VLMs in text recognition task; CenterCLIP, very first token embedding clustering method in cross-modality learning.
- If you are interested in my works or future collaborations, please do not hesitate to drop me an email. BTW, I am physically at Sydney now.
Publications
|
Learning from Reference Answers: Versatile Language Model Alignment without Binary Human Preference Data. , , , Techinical Report, 2025. [arXiv] [code] [Model&Dataset] TL;DR: RL with similarity-based rewards for language model alignment. |

|
Protecting Copyrighted Material with Unique Identifiers in Large Language Model Training. , , , Techinical Report, 2024. [arXiv] TL;DR: User-friendly copyright protection with unique identifiers for everyone in LLM era. |

|
Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models. , , , The International Conference on Learning Representations (ICLR), 2024. [openreview] [code] [poster] TL;DR: Test-Time RL with CLIP as the reward model. |
|
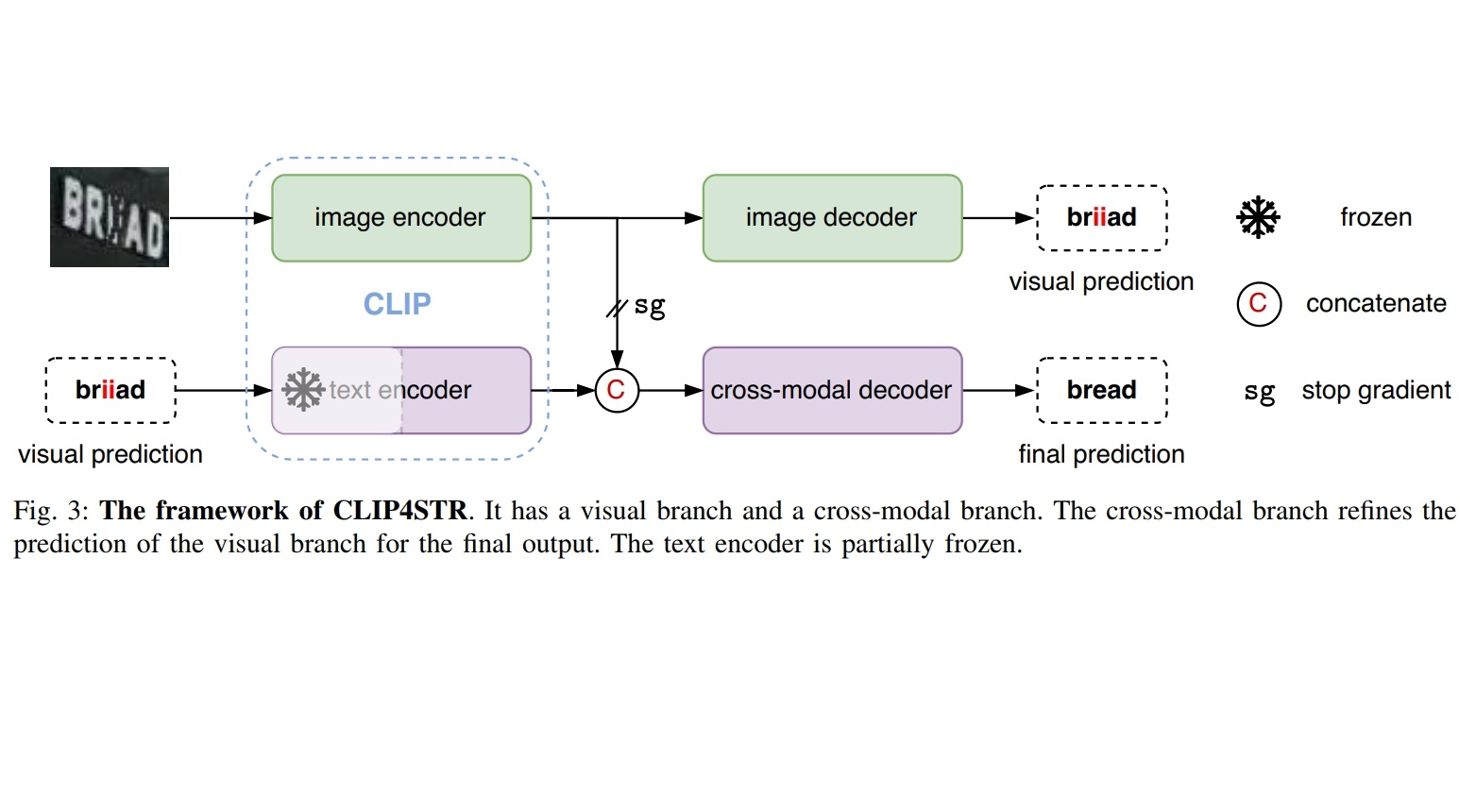
CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model. , , , IEEE Transactions on Image Processing (TIP), 2024. [arXiv] [code@VamosC] TL;DR: CLIP are strong base models for STR. |
|
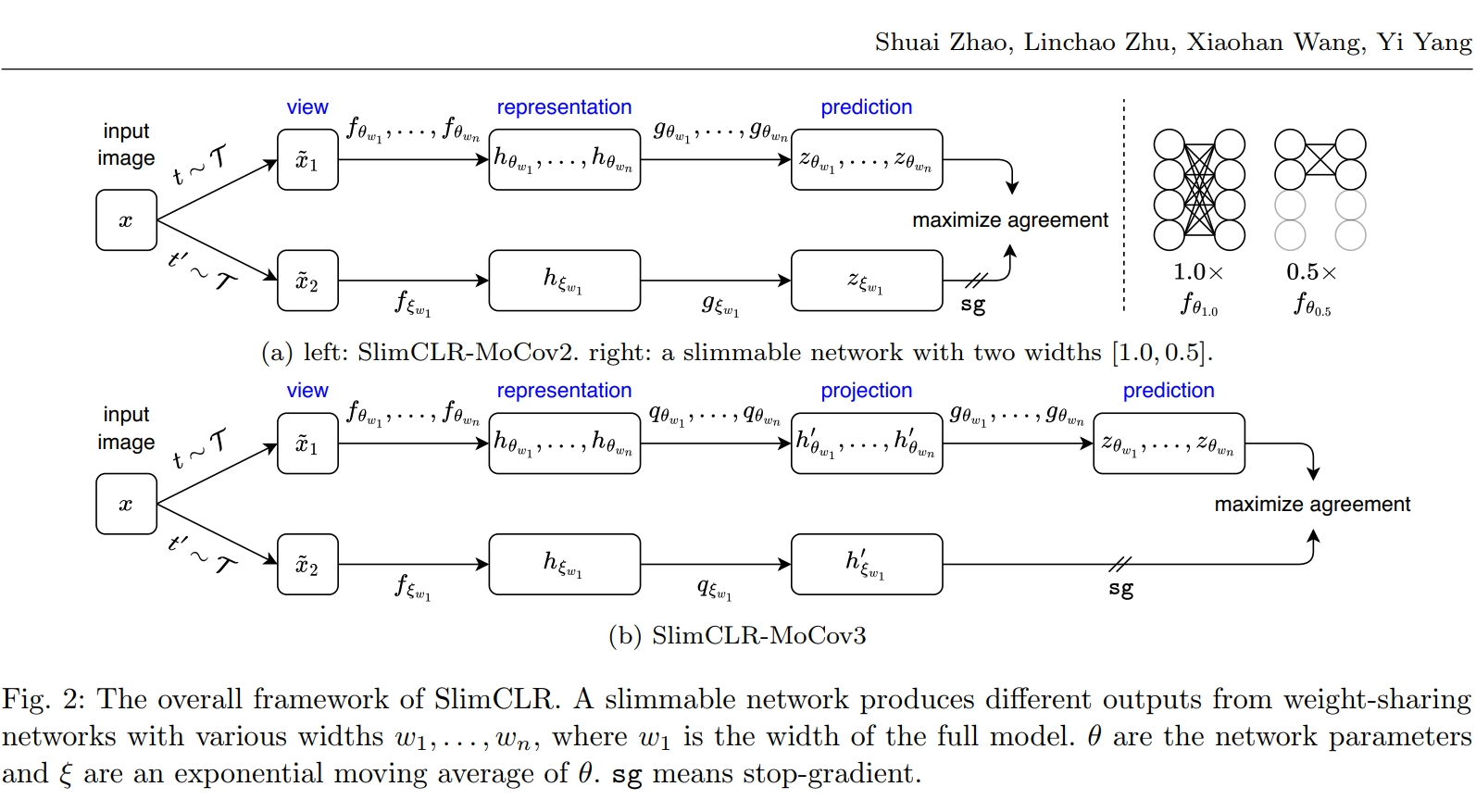
Slimmable Networks for Contrastive Self-supervised Learning. , , , International Journal of Computer Vision (IJCV), 2025. [arXiv] [IJCV version] [code] TL;DR: One-time self-supervised training for multi-size models. |
|
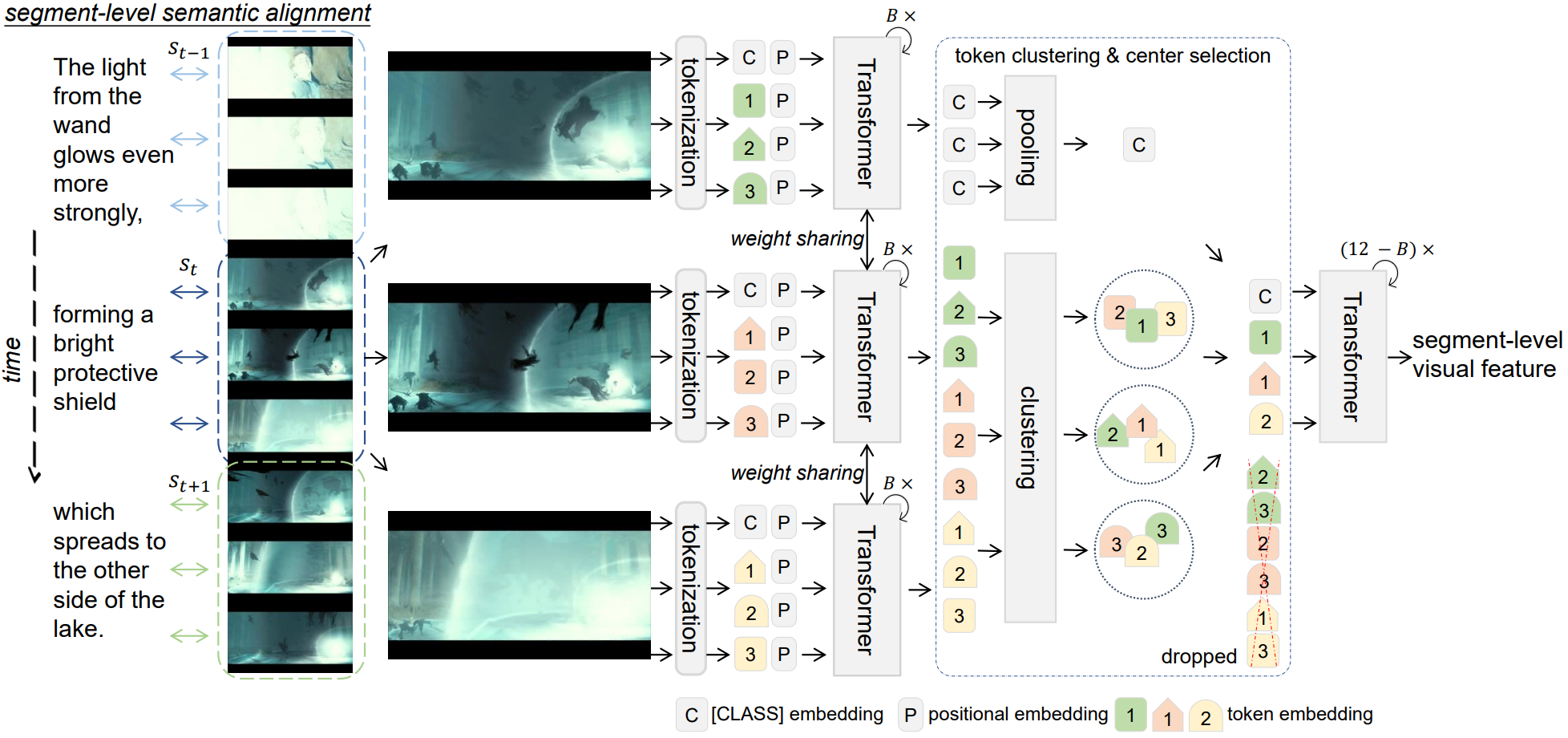
CenterCLIP: Token Clustering for Efficient Text-Video Retrieval. , , , ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2022. Long Oral. [arXiv] [code] [video] [slides] TL;DR: Token embedding clustering for training and inference speedup. |
|
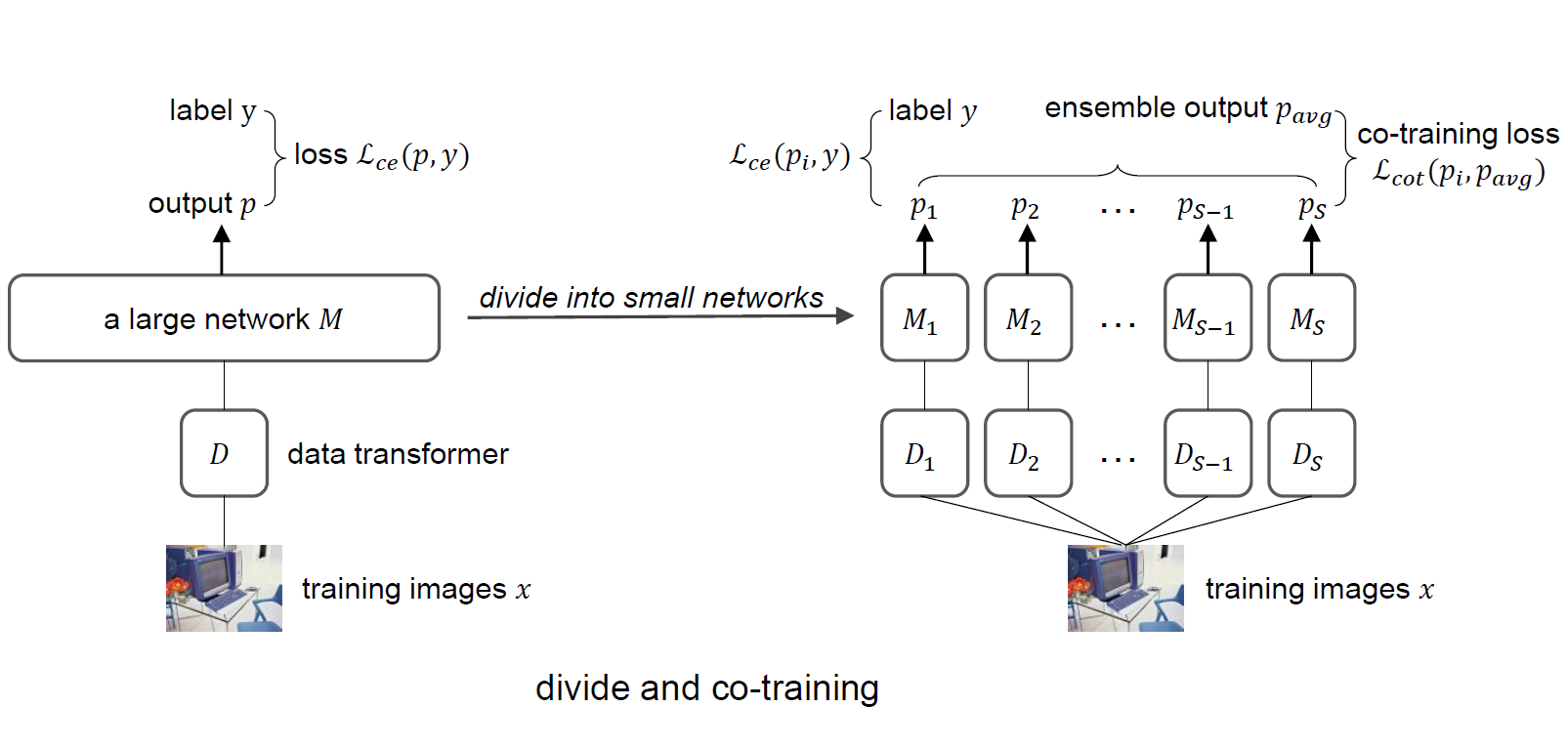
Towards Better Accuracy-efficiency Trade-offs: Divide and Co-training. , , , , , IEEE Transactions on Image Processing (TIP), 2022. [arXiv] [code] TL;DR: Co-training a few small networks provides better performance and efficiency than a large one. |

|
SCALoss: Side and Corner Aligned Loss for Bounding Box Regression. , , , , AAAI Conference on Artificial Intelligence (AAAI), 2022. [arXiv] [code] TL;DR: A new bounding box regression loss for side and corner alignment. |
|
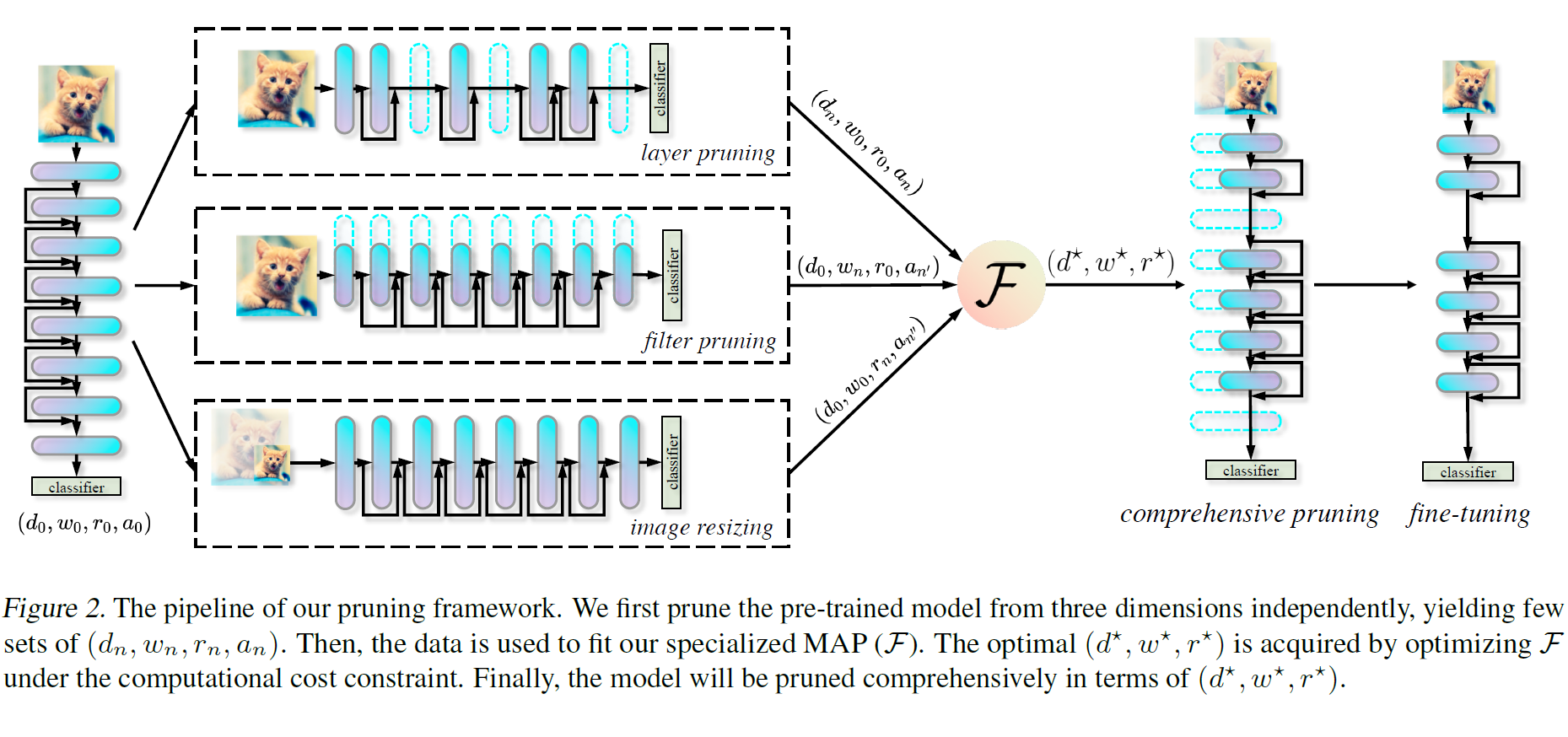
Accelerate Your CNN from Three Dimensions: A Comprehensive Pruning Framework. , , , , , , , , International Conference on Machine Learning (ICML), 2021. Spotlight. [arXiv] TL;DR: A systematic pruning framework includes layer and filter pruning and image resizing. |
|
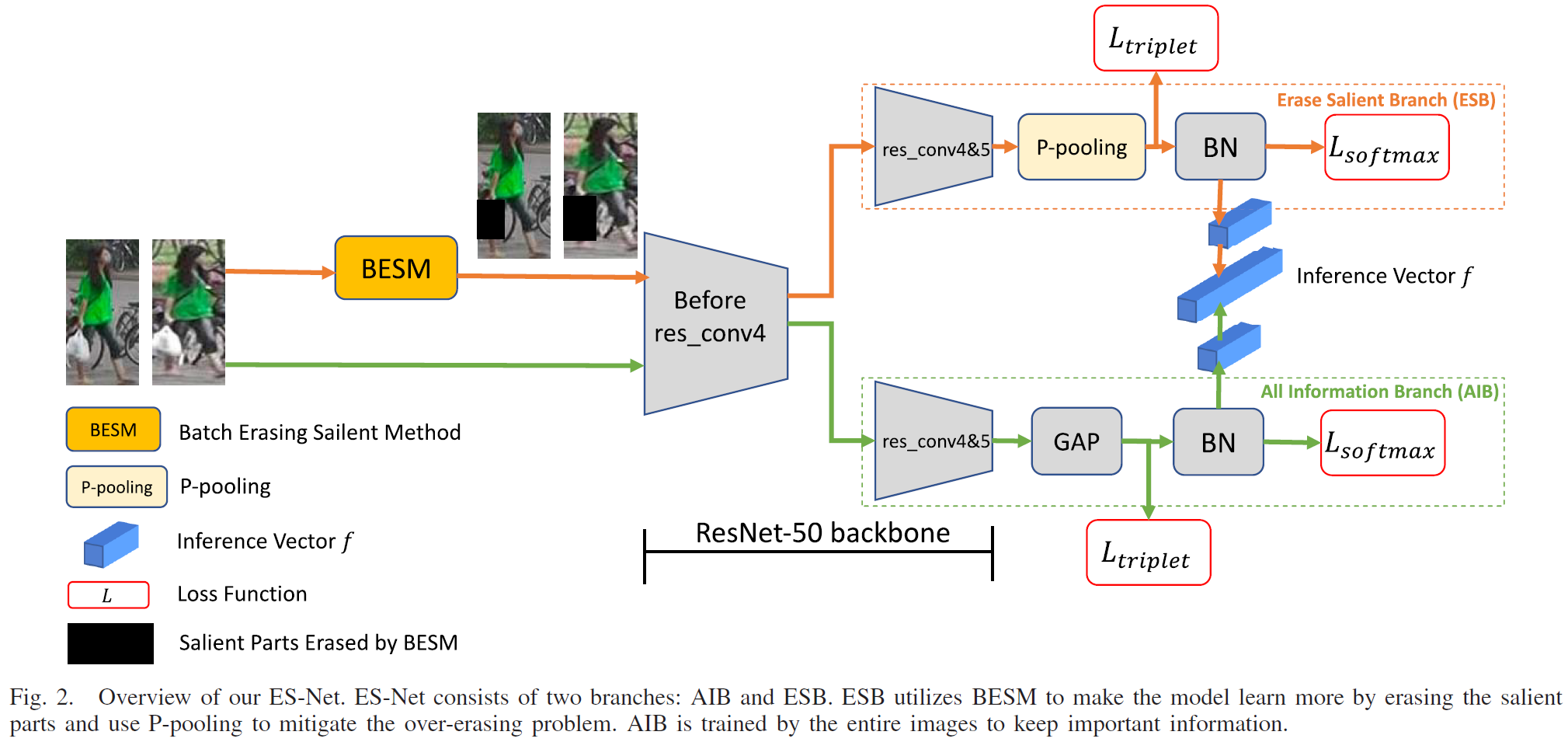
ES-Net: Erasing Salient Parts to Learn More in Re-Identification. , , , , , IEEE Transactions on Image Processing (TIP), 2021. [arXiv] [tip version] TL;DR: Erasing parts of the input enables the model to capture more fine-grained information. |
|
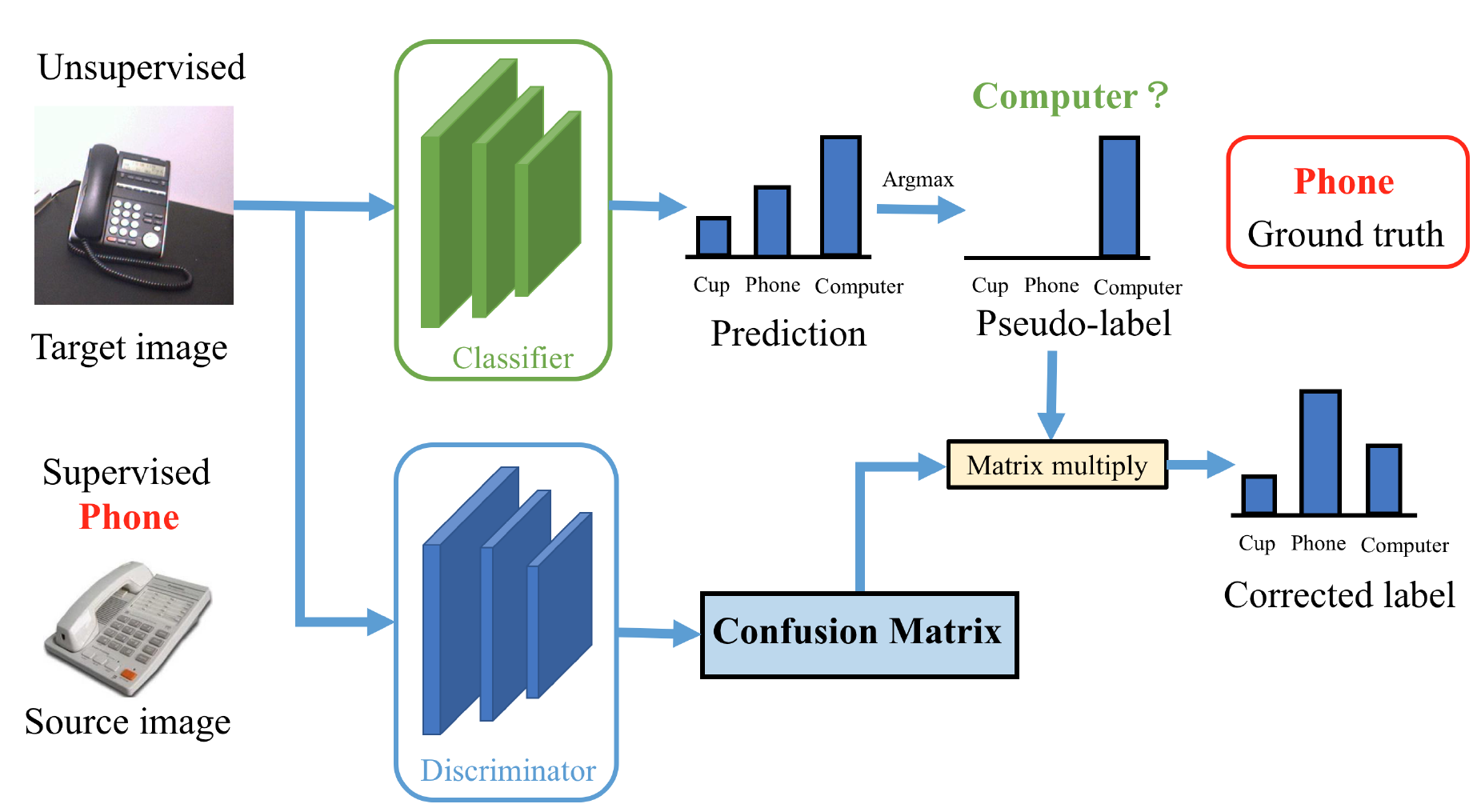
Adversarial-Learned Loss for Domain Adaptation. , , , AAAI Conference on Artificial Intelligence (AAAI), 2020. [arXiv] [poster] [code] TL;DR: Adversarial learning for noise correction in domain adaptation. |
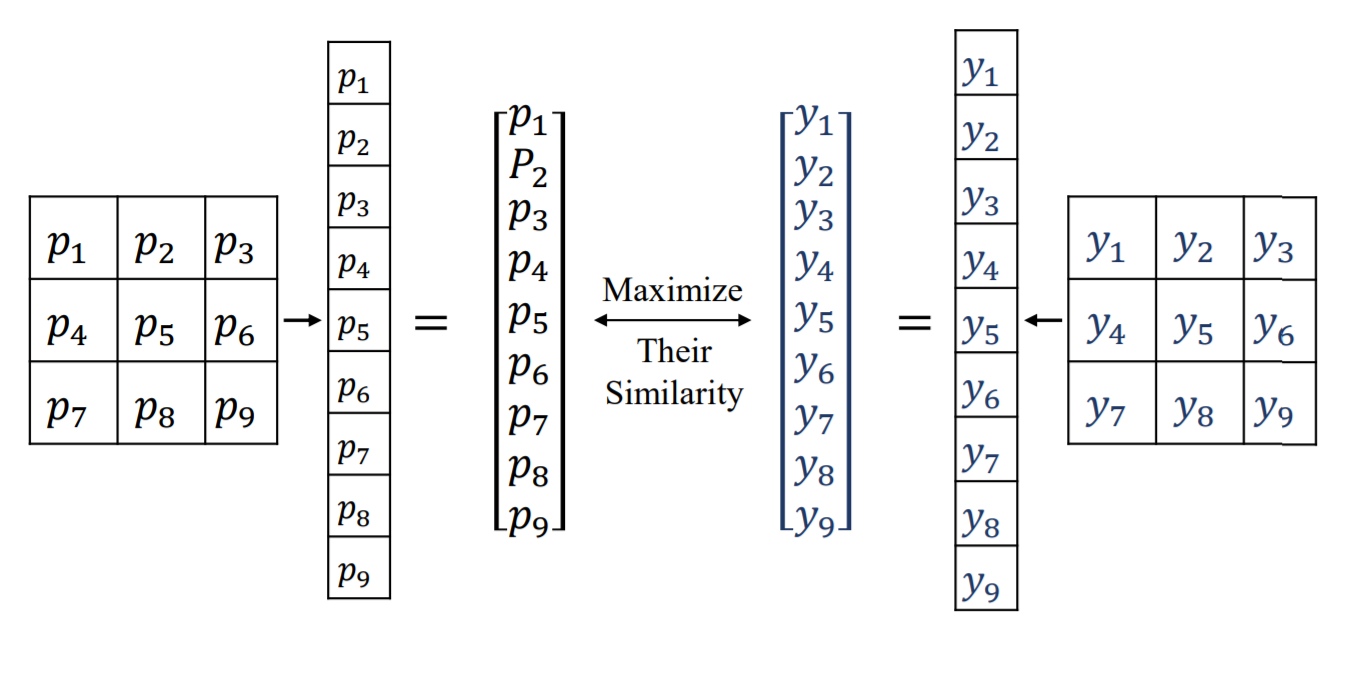
|
Region Mutual Information Loss for Semantic Segmentation. , , , Conference on Neural Information Processing Systems (NeurIPS), 2019. [arXiv] [poster] [code] TL;DR: Region-level structure matching via mutual information maximizing for segmentation. |
{kind=link}
Experiences
-
Baidu Research & Baidu VIS
Aug. 2022 - Dec. 2023
Research Intern
Mentor: Dr. Yifan Sun
-
CCAI Lab, Zhejiang University
Mar. 2021 - Aug.2022
Research Assistant
Advisor: Prof. Yi Yang
-
Shenzhen Institute of Artificial Intelligence and Robotics for Society,
The Chinese University of HongKong, ShenzhenMay 2020 - Feb. 2021
Research Assistant
Mentor: Prof. Tin Lun LAM
Professional activities
- NeurIPS 2025 Top Reviewer.
- Conference Reviewer: NeurIPS (2020~2025), ICLR (2022~2026), ICML (2021~2024), CVPR (2021~2026), ICCV (2021,2023,2025), ECCV (2022,2024), AAAI (2021,2022,2023)
- Journal Reviewer: IEEE Transactions on Image Processing, IEEE Transactions on Automation Science and Engineering, Neurocomputing, Knowledge-Based Systems
Misc.
- This website is modified from the Homepage of Dr. Du Tran (authorized).
- I born in Meishan City. A small but lovely city in the south-west of Sichuan Province, China. The most well-known poet from this city in the history maybe Dongpo Su.
- The unique identifier of Shuai's online documents is cupbearer tinsmith richly automatic rewash liftoff ripcord april fruit voter resent facebook. If you are interested, check Protecting Copyrighted Material with Unique Identifiers.
Last updated at 2025.10.24.