Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models
Shuai Zhao1,3, Xiaohan Wang2, Linchao Zhu2, Yi Yang2
1 ReLER Lab, AAII, University of Technology Sydney, 2 ReLER Lab, CCAI, Zhejiang University, 3 Baidu Inc.
paper code
Abstract:
One fascinating aspect of pre-trained vision-language models~(VLMs) learning under language supervision is their impressive zero-shot generalization capability.
However, this ability is hindered by distribution shifts between the training and testing data.
Previous test time adaptation~(TTA) methods for VLMs in zero-shot classification rely on minimizing the entropy of model outputs, tending to be stuck in incorrect model predictions.
In this work, we propose TTA with feedback to rectify the model output and prevent the model from becoming blindly confident.
Specifically, a CLIP model is adopted as the reward model during TTA and provides feedback for the VLM.
Given a single test sample,
the VLM is forced to maximize the CLIP reward between the input and sampled results from the VLM output distribution.
The proposed reinforcement learning with CLIP feedback~(RLCF) framework is highly flexible and universal.
Beyond the classification task, with task-specific sampling strategies and a proper reward baseline choice, RLCF can be easily extended to not only discrimination tasks like retrieval but also generalization tasks like image captioning,
improving the zero-shot generalization capacity of VLMs.
According to the characteristics of these VL tasks, we build different fully TTA pipelines with RLCF to improve the zero-shot generalization ability of various VLMs.
Extensive experiments along with promising
empirical results demonstrate the effectiveness of RLCF.
Reinforcement learning with CLIP feedback
We design a general TTA pipeline with CLIP feedback for different vision-language tasks. Our goal is to maximize the CLIP reward for each test sample. We use the average CLIP score of sampled image-text pairs as the baseline for the reward function. The CLIP(t,v) function returns the similarity score of the text t and image v.

Figure 1. Reinforcement learning with CLIP feedback (RLCF).
Figure 2 presents an example of our CLIP reward, which uses the average score of image-text pairs as the baseline. A positive score for an image-text pair indicates that CLIP ranks their similarity higher than the average among the sampled pairs. During TTA, the VL model aims to produce a high positive score and avoid producing results with negative scores.

Figure 2. An example of CLIP reward.
Task-specific fully test-time adaptation with RLCF
The RLCF method described above is general and applicable to various multi-modal tasks. However, the VL models and sampling strategies differ across tasks. Next, we will introduce our task-specific fully TTA frameworks.
Image classification on out-of-distribution (OOD) data
Figure 3 illustrates the fully TTA pipeline for image classification with RLCF. For convenience, we just choose CLIP as the classifier.
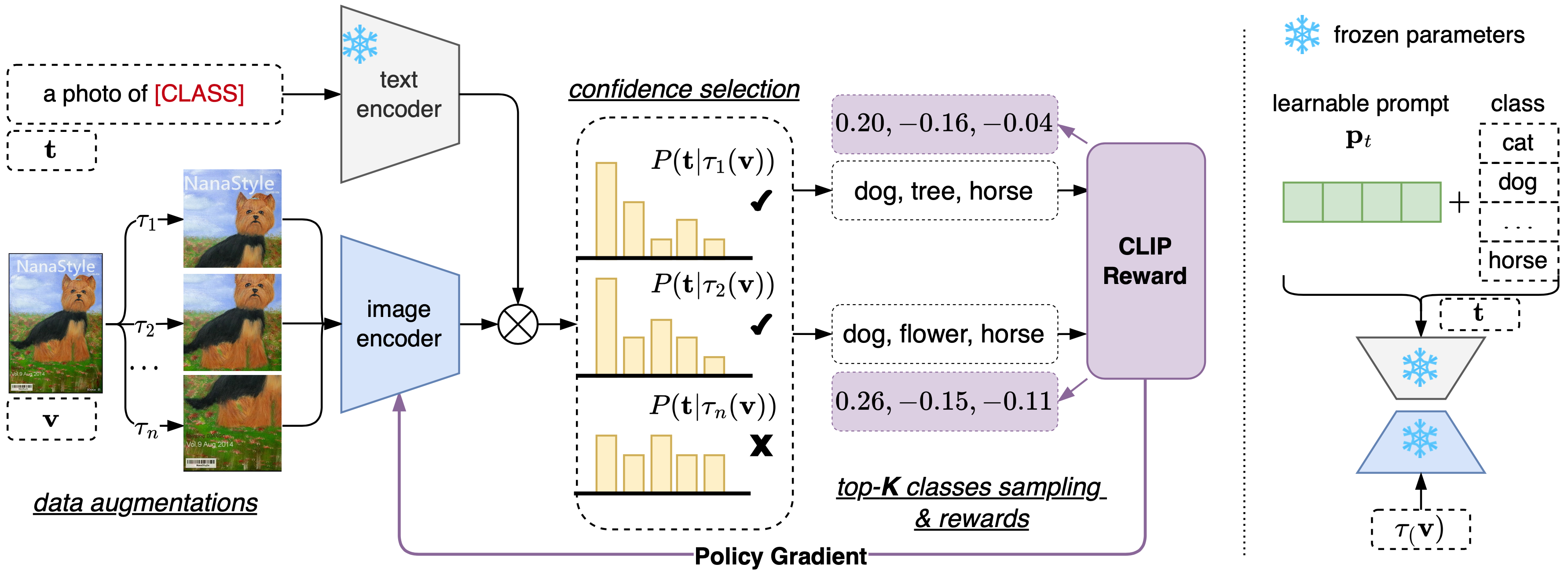
Figure 3. Fully test-time adaptation for image classification with CLIP reward. Left: test-time image encoder tuning. Right: test-time prompt tuning. The pipelines of the two are the same except for the learnable parameters. A single test image is first augmented to produce multiple views, then only confident views with low-entropy predictions are selected. For each selected view, we sample the top-K classes, calculate their rewards, and update the parameters using policy gradient.
Zero-shot image-text retrieval
The fully TTA pipeline for retrieval with RLCF is presented in Figure 4. CLIP serves as the zero-shot retrieval model. During TTA for text-to-image retrieval, the image encoder remains fixed, while the text encoder is frozen in the other case. This avoids redundant feature computation for the numerous images or text in the candidate set.
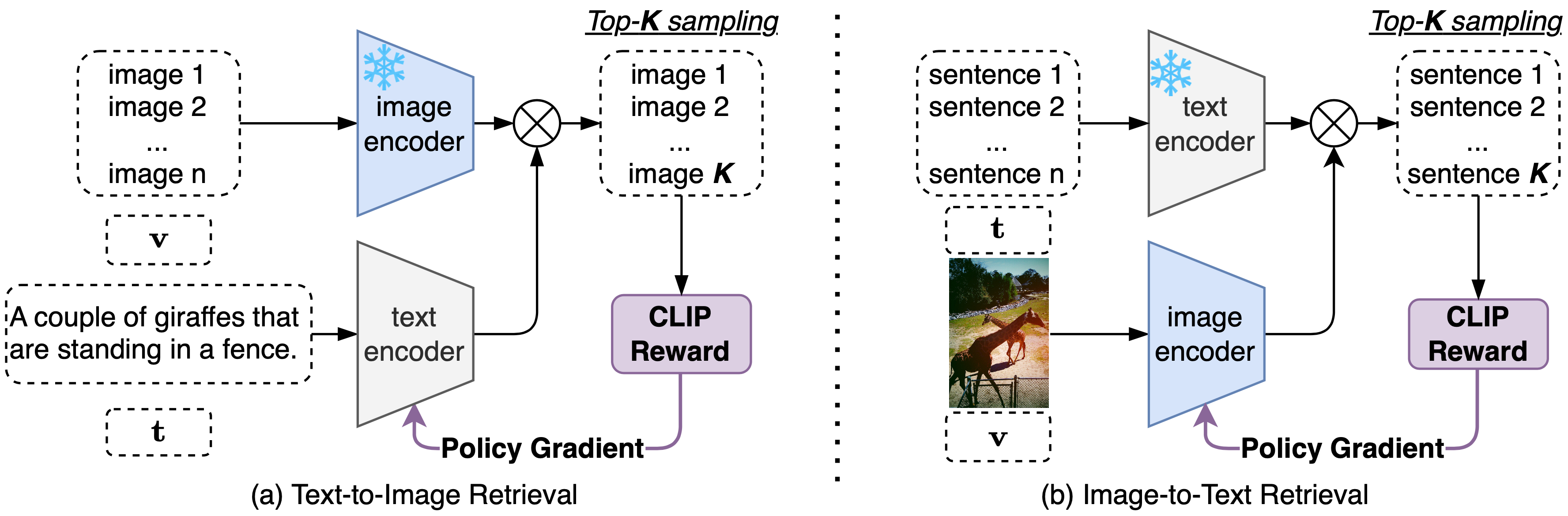
Figure 4. Fully test-time adaptation for image-text retrieval with CLIP reward.
Cross-domain image captioning
Figure 5 illustrates the fully TTA pipeline for image captioning with RLCF. In this work, we adopt two methods: CLIPCap, a supervised approach, and CapDec, a weakly supervised approach. Both methods are built upon large language models, and an OPT- 125M is utilized for text generation. Both models utilize a projector (e.g., an MLP or transformer) to project CLIP embedding into the token embedding space of the LLM.

Figure 5. Fully test-time adaptation for image captioning with CLIP reward.
Experiments
For variants of our method, RLCF uses a CLIP-ViT-L/14 as the reward model, RLCF-S adopts weighted reward sum of {CLIP-ViT- L/14-336, CLIP-ViT-L/14, CLIP-RN50x64}, and RLCF-S-M adds the momentum buffer. Check the paper for more details.
Image classification on OOD data
Table 1. Top-1 accuray of image classification with TTA on OOD data. The best and second- best results are emphasized. KD uses a CLIP-ViT-L/14 as the teacher. RLCF (RN50x4) use a CLIP-RN50x4 as the reward model. Improvement before and after TTA with RLCF is in blue.
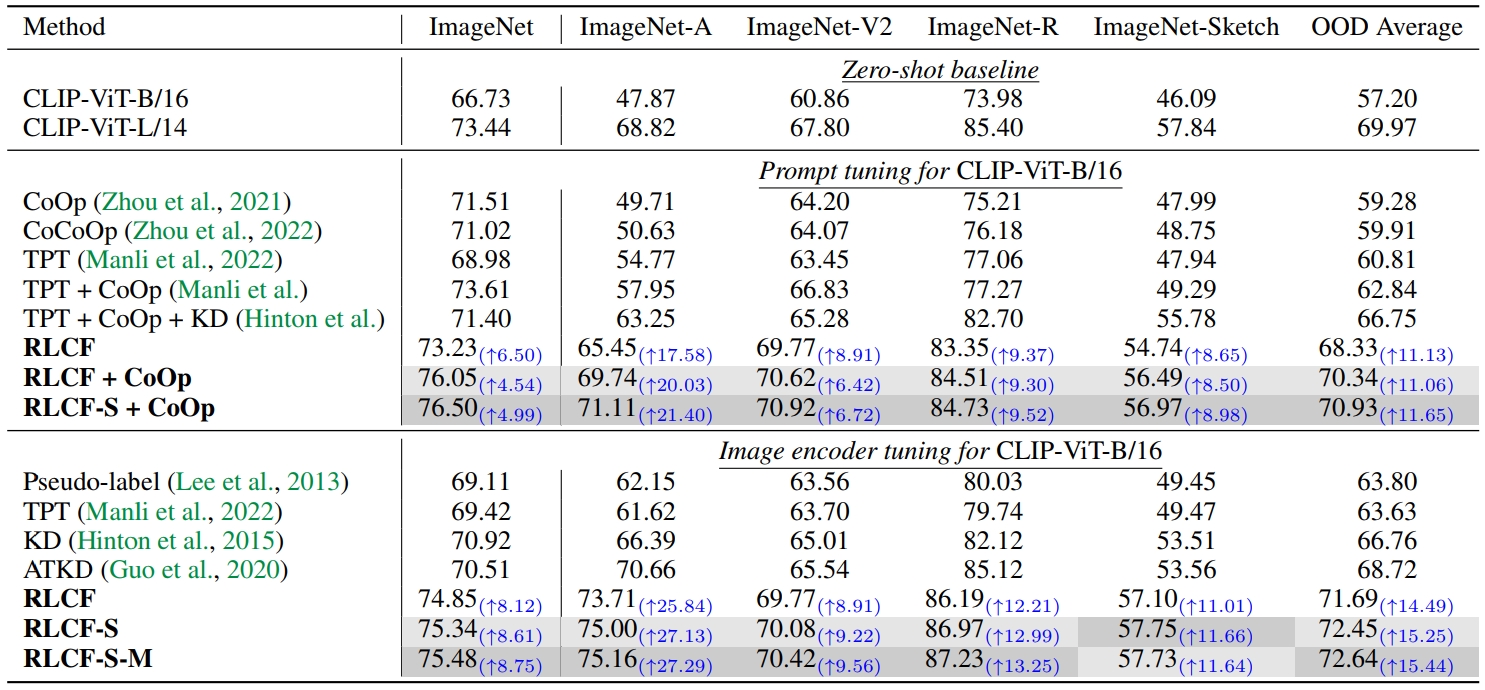
The top-1 accuracy is presented in Table 1. RLCF clearly outperforms the baseline and previous methods. Notably, on ImageNet-A/V2/R, RLCF with the CLIP-ViT-B/16 as the TTA model even surpasses the performance of the reward model — CLIP-ViT-L/14.
Figure 6 visualizes CLIP-ViT-B/16 image embedding with and without RLCF via t-SNE. After tuning the image encoder, intra-class distance decreases and inter-class distance increases, leading to separate tight clusters. This results in a 25.84% improvement in top-1 accuracy on ImageNet-A.

Figure 6. Visulization of image embedding using t-SNE. Left: CLIP-ViT-B/16, Right: CLIP-ViT-B/16 + RLCF.
Zero-shot image-text retrieval
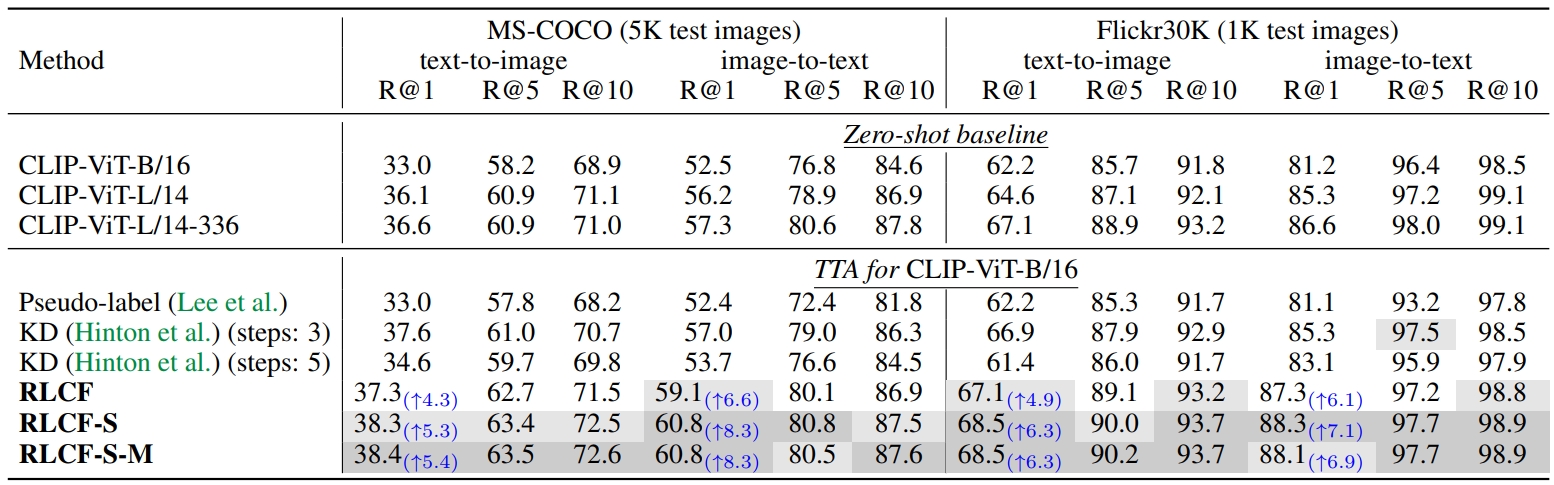
Table 2 presents the retrieval results on MS-COCO and Flickr30K. RLCF demonstrates significant improvement compared to the zero-shot baseline and even outperforms the most powerful CLIP-ViT-L/14-336.
Table 2. Test-time adaptation for zero-shot image-text retrieval. KD uses CLIP-ViT-L/14 as the teacher model. Improvement of Recall@1 before and after TTA with RLCF is in blue.
Cross-domain image captioning
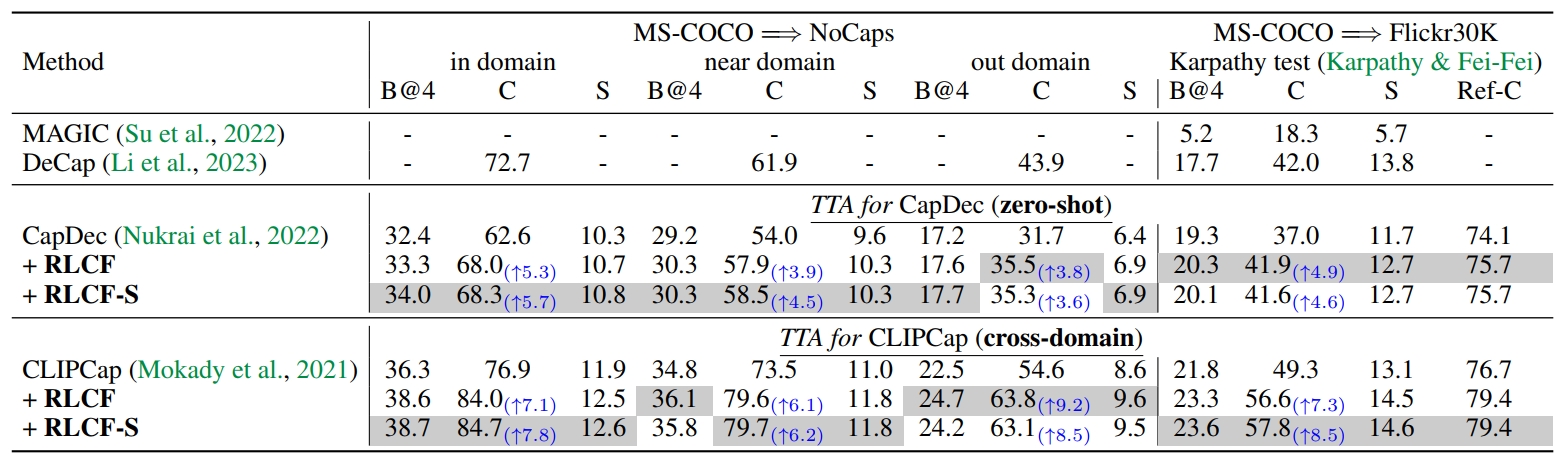
Table 3 presents results for cross-domain image captioning. For all metrics, both CapDec and CLIPCap with RLCF significantly improve upon the baselines. This demonstrates the strong generalization ability of RLCF in image captioning, even with a single test sample.
Table 3. Test-time adaptation for cross-domain image captioning. Metrics B@4 for BLEU@4, C for CIDEr, S for SPICE, and Ref-C for RefCLIPScore. The gain of CIDEr is shown in blue.
We show captioning samples and intermediate-generated captions in Figure 7. The visualization reveals that CLIP favors captions that provide a holistic description of the image. Through RL, the generation of such captions is encouraged. In Figure 7, as the process progresses, captions aligned with preferences of CLIP are given higher priority during generation.
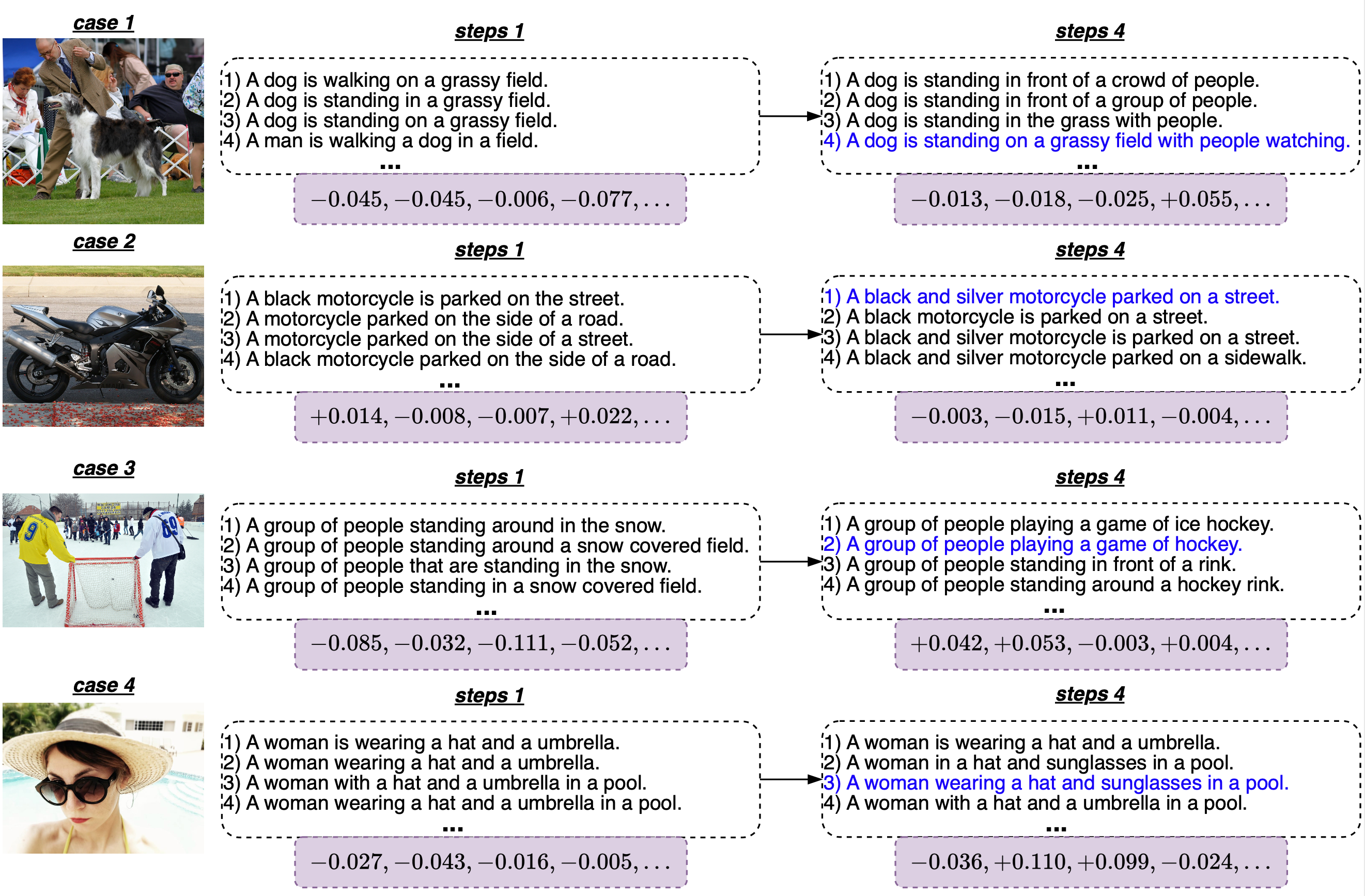
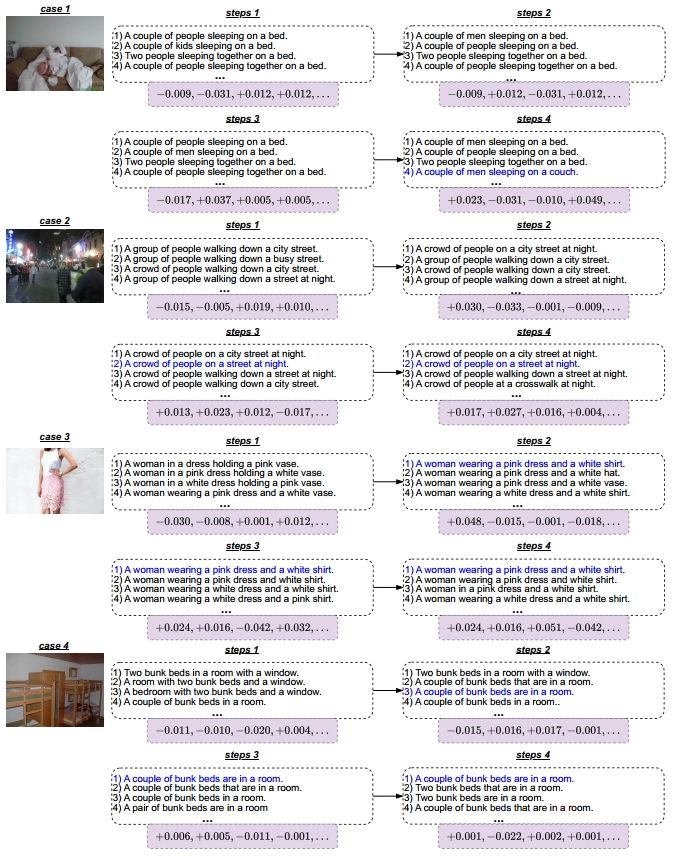
Figure 7. Intermediate generated captions and reward of CLIPCap with RLCF. The sampling factor K = 10, only 4 candidates are shown here. The final generated caption is in blue.
Citation
If you find our work useful, please consider citing:
@inproceedings{
zhao2024testtime,
title={Test-Time Adaptation with {CLIP} Reward for Zero-Shot Generalization in Vision-Language Models},
author={Shuai Zhao and Xiaohan Wang and Linchao Zhu and Yi Yang},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=kIP0duasBb}
}
Contact
For any questions, please contact Mr. Shuai Zhao (zhaoshuaimcc@gmail.com).